




Appsmith is an open-source low code platform for developers to build internal apps and workflows.
In Appsmith, our developer users define business logic by writing any JS code in between {{ }} dynamic bindings almost anywhere in the app. They can use this while creating SQL queries, APIs, or triggering actions.
This functionality lets you control how your app behaves with the least amount of configuration. Underneath the hood, the platform will evaluate all this code in an optimized manner to make sure the app remains performant yet responsive.
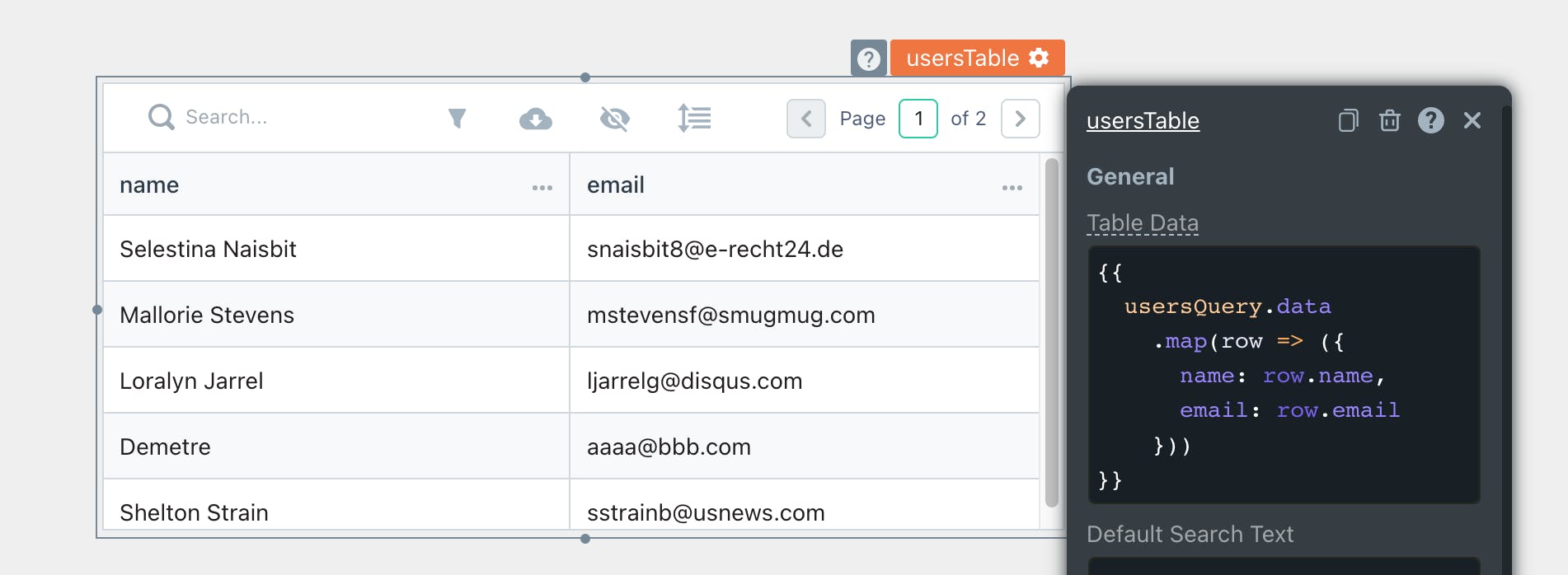
Let us take an example of binding a query response to a table widget.
It all starts with the binding brackets {{ }} . When the platform sees these brackets and some code in it, in a widget or action configuration, it will flag the field as a dynamic field so that our evaluator can pick it up later. In our example let us bind usersQuery to usersTable
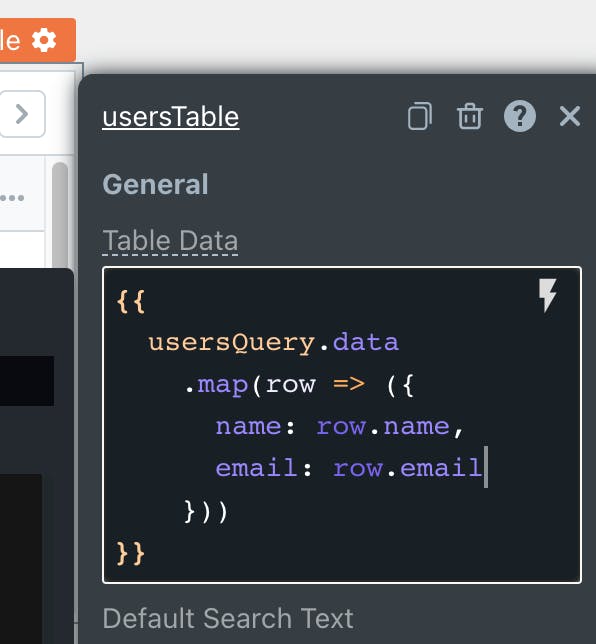
Since we have added this binding in our tableData field, we will flag this field and store it in our widget config
// usersTable config
{
"usersTable": {
...
"tableData": "{{
usersQuery.data
.map(row => ({
name: row.name,
email: row.email
}))
}}",
"dynaminBindingPathList": [
{"key": "tableData"}
...
]
}
}
In the background, our evaluation listener, always keeps a lookout for such events that would need an evaluation. For our example, this is a scenario that definitely needs an evaluation, so it kicks off our evaluator.
We pass on our current list of app data constructed in what we call as DataTree to the evaluator thread and patiently wait to hear back from it ⏱
// DataTree
{
"usersQuery": {
"config": {...},
"data": [...]
},
"usersTable": {
"tableData": "{{
usersQuery.data
.map(row => ({
name: row.name,
email: row.email
}))
}}",
"dynaminBindingPathList": [{"key": "tableData"}]
}
}
For performance reasons, we run our evaluation process in a separate background thread with the help of web workers. This ensures that evaluation cycles running longer than 16ms do not hang up the main thread giving the app bandwidth to always respond to user events.
Inside the thread, the event listener gets a wake-up call and gets to work.
Get differences: First it will calculate differences in the
DataTreefrom the last time. This will ensure we only process changes and not the whole tree.In our example, we would see the
usersTable.tableDatahas changed andusersTable.dynamicBindingPathListhas a new entry.It takes each difference, filters any un-important changes, and processes the rest.
Get evaluation order with dependency map: It also maintains a
DependencyMapbetween various entity properties. The evaluator will notice if any bindings have changed and recreate the sort order accordingly.For our example, we will infer that
usersTable.tableDatanow depends onusersQuery.data. This means that the query response should always be evaluated before we can evaluate the table data and that whenever we see a change in the query response, we need to re-evaluate the table data as well// DependencyMap { ... "usersTable.tableData": ["usersQuery.data"] } // Evaluation order [ "usersQuery.data", "usersTable.tableData" ]Evaluate: After creating an optimized evaluation order, we will evaluate the update the tree, in that said order. Evaluation happens via a closed
evalfunction with the wholeDataTreeacting as its global scope. This is why we can directly reference any object in ourDataTreein our code.// Evaluator const code = ` usersQuery.data.map(row => ({ name: row.name, email: row.email })) `; const scriptToEvaluate = ` function closedFunction () { const result = ${code}; return result } closedFunction() `; const result = eval(scriptToEvaluate);Validate and parse: We always want to make sure the values returned after evaluation to be in the right data type that the widget expects. The ensures the widget always gets predictable data even if your code has returned some errors. This is also needed for any function down the line in the evaluation order, if it refers to this field, will always get a reasonable data type to work with.
And that completes it. At the end of this, we will have a fully evaluated DataTree that we can then send back to the main thread and start listening for any new event to do this whole process again.
// Evaluated DataTree
{
"usersQuery": {
"data": [...]
}
"usersTable": {
"tableData": [...]
}
}
Our main thread gets an event saying the evaluation is complete, with the new evaluated DataTree which it stores in the app redux state. From here, the widgets pick up their data and render it.
Summarizing our philosophy
Pull vs Push: While building a low code app builder for varied developers, we thought hard about how the written code works with the rest of the platform. We wanted configuration to be easy to start yet powerful when it needed to be. For this reason, we went with a Pull based architecture rather than Push.
What this means is that in most places, you won't have to think about how the data will get to a field. You write code that pulls everything from the global
DataTreeand sets it to the field where you write it. This way the moment the underlying data changes, it get propagated to all the fields dependant on it and you as a developer do not have to orchestrate ui changes.One-way data flow: Since we are built on top React.js and Redux, we strongly embrace the one-way data flow model.
What this means is that you cannot set a table's data directly to that field from some other part of the app. If you do need to update the table, you will have to trigger the query to run, which will then cause the table to re-render with the new data. This helps the code you write easy to reason about and bugs easy to find. It also encapsulates each widget's and action's logic in itself for good separation of concern.